I’ve been recently asked about my approach to software estimation (with a follow on regarding planning), here are my thoughts on the matter.
When talking to whomever is asking for the estimate/plan, it is imperative to clarify that these are indeed simply estimates and are going to be wrong. As Steve McConnell has shown in his book Software Project Survival Guide, the further away from the end of the project, the less accurate the estimate:
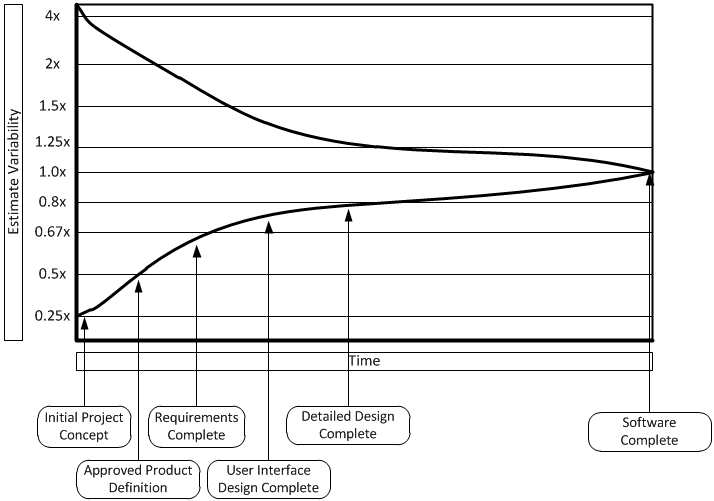
Unfortunately, there’s a tendency to take estimates and turn them into deadlines – it is an easy trap to fall into and is something we all do.
Estimating, the right way
Luckily there’s a simply solution to this issue:
Never provide a single value as an estimate – give a range.
A range? Absolutely – it immediately conveys the amount of uncertainty that is inherent in the estimate. It gives your stakeholders something concrete to base plans on, and the ability to add risk assessment and mitigation options to their plans. Saying that “this project is estimated to take between two weeks and four months” tells people how much is unknown and uncertain about the project. This is a good thing.
But how do I get this range? What estimation process would provide it?
The lower number is simple – it is likely what you already do when you estimate (whether alone or with your team) – it is the estimate most developers give when asked for an estimate, the optimistic, “nothing will go wrong” estimate, the “this is how long things should take, all else being equal”. It is the estimate that ignores many possible issues and delays.
But how to get to the higher number? While estimating, after getting the lower number, ask – how would this change if something delayed the work? Examples of which are: major refactoring, new feature in a library that the code depends on, hardware provisioning etc… – I am sure you can come up with other scenarios that are suitable to whatever task is being estimated. I suggest using something plausible – best if it is such an issue that has happened in the past with a similar task. I find that assuming such a monkey wrench thrown into the works tends to change the estimates drastically. Which is exactly what I am looking for.
And here you have it – an estimate range, with built in uncertainty :)
But, I hear you ask, what if the scope isn’t clear? What do to if the task cannot be broken down? How do I deal with changes?
These are all valid – and the answers are – if the scope isn’t clear, try to clarify it as much as possible. If this requires research in order to gain some understanding of the issue – that’s good. The research should give you an idea about what is required and the different large items that are needed and how long they should take (again – a range, from optimistic to pessimistic).
Additionally, most tasks *can* be broken down, to large components, if nothing else. Again, research helps here.
And changes? They require re-estimation. Figure out what needs to change as the requirements change (if lucky, nothing already done needs to be changed). Estimate the re-work required, estimate the new requirements and, remove old no longer needed tasks and presto – a new set of estimates, with the changes included.
Planning, the right way
Another thing I like to do with task/project estimations is to break things down to knowns and unknowns, where knowns are tasks that are familiar – these are items that are very similar to things that have already been done by the team, so are a known quantity – people know how long the similar item took, so there’s some confidence in getting an accurate estimate.
But what about the unknowns? And I class the following into that: new language, library or platform. As well as any project/task that largely deviates from things that have been previously done by the team (including things in much larger scale or that depends on a new vendor). With these, it is best to break down to individual items – and keep breaking down till you get to known items or small tasks (small meaning – estimated at a few hours). The broken down items should be estimated in the same way as above.
The end result should be a fully estimated set of tasks – each with a low and high estimate, the range of which should convey the uncertainty in the estimate. A bunch of these tasks would naturally be grouped to larger tasks/projects – the larger estimate range for those is simply the sums of each of the ranges (i.e. – add up the lower estimates to get the aggregate lower estimate and the same for the higher estimate).
At this point, you have a list of features with estimate ranges that you can show your stakeholders (or, better yet, a product manager, if you are lucky enough to have one) for planning and prioritising.
Hopefully, that list of features makes sense – it is best to cluster tasks to groups that make sense as whole features or related features – and try to get some coherence across the board (you will find some items conflict with each other or are at complete opposites) – you and your product manager will need to make sense of those.
I suggest prioritising by what would bring most benefit to the business.
If at all possible, ensure tasks can be worked on independently and delivered independently – this means you can have something to show earlier, possibly even something you can deploy so the business/client can get some value from it as soon as possible. This has an added benefit of shortening the feedback cycle – any new features or bug fixes happen earlier. It is a virtuous cycle.
Another thing to do is try and simplify the features and tasks as much as possible. If you can cut 20% of a feature to deliver it 80% faster? That’s a massive win. Most of the time, you will find that gold-plating a feature is wasted time. Being able to only do the simple thing instead of accounting for all edge cases and possible uses is a boon – it is a form of YAGNI, and most of the time, you really won’t miss out on things.
